이번 글은 Language Model are Few-Shot Learners라는 GPT-3의 논문에 대해서 간략하게 살펴보겠습니다.
GPT-3 논문에 Abstract를 살펴보면, 다음과 같습니다.

기존에는 PLM을 finetuning하여 모델을 학습시켜 사용했습니다. PLM이 출연해서 어떤 task를 학습하는데 있어서 굉장히 많은 양의 데이터가 필요해지지 않게 되었습니다. 하지만 여전히 천 ~ 만 단위 이상의 데이터 셋이 필요하고, 사람의 경우 적은 예제나 instruuction만으로도 작업이 가능한것에 비해서 딥러닝 모델은 많은 양에 데이터가 필요합니다.
Autoregressive LM의 크기를 키워 방대한 데이터로 학습을하면 사람과 같이 적은 예제와 instruction만으로도 작업이 가능하게 됨을 알 수있었다고 합니다.
GPT-3 논문에서는 방대한 양의 연구 및 실험을 수행했고 해당 내용들을 논문에 작성을 했습니다.
GPT-3에서는 Fine Tuning 방법의 문제점을 이야기하면서 메타러닝을 제안했습니다. Fine Tuning 방법은 새로운 Task를 풀 때마다 많은 양의 레이블링이 된 데이터가 필요합니다. 다량의 지식을 학습하거나 특정 task에 fine tuning 될 때, 일반화 능력을 상실하게 된다는 단점이 있다고 소개하고 있습니다. 이러한 단점에 비해서 사람의 경우 대규모 라벨링된 데이터 가 없어도 간단한 지시나 예시로도 학습이 가능합니다. GPT-3 논문에서는 Fine Tuning의 문제점을 해결하고, 적은 양에 라벨링 된 데이터로 사람과 유사하게 학습과 예측을 할 수 있는 메타러닝을 제시합니다.
최근 언어 모델의 추세는 Parameter의 수가 증가하는 추세입니다. Parameter의 수를 증가시키는 이유는 Parameter의 수가 증가하면 할 수록 모델의 성능이 향상 되기 때문입니다. 예를들면 Bert는 3억, GPT-2는 14억, Megatron 80억 T5는 110억, Project Turing 170억개의 Parameter를 가지고 있습니다.
이렇게 Parameter의 수가 증가하면 할 수록 downstream에서의 task에서 성능이 개선되었고, Parameter의 규모가 커지면 커질 수록 log loss가 개선되는 것을 알 수 있었다고 합니다.
위의 사진은 meta learning의 예시입니다. LLM에서의 meta learning은 앞에 내용을 보고 뒤에 나올법한 적절한 내용을 예측을 하는 것입니다. 즉, 이러한 메타러닝 학습 방법을 어떤 context가 주어졌을 때, 정답을 만들어 낼 수 있는 능력을 Incontext learning이라고 합니다.
논문에서는 Incontext Learning 방식은 모델의 사이즈가 커지면 커질 수록 많은 스킬과 task를 습득을 할 수 있기 때문에 in-context-learning으로 모델을 개선할 여지가 있다고 합니다.
논문에서는 24개 이상의 NLP task에 대해 3가지 조건을 이용하여 GPT-3를 평가했습니다.
- few-shot learning(in-context-learning) : 모델의 context window(10 - 100)에 최대한 많은 예제를 넣음
- one-shot learning : 하나의 예제만 넣음
- zero-shot learning : 예제는 넣지 않고, task에 대한 지침만 넣음
위에 3가지 학습 방법을 간단하게 정리하면 아래와 같습니다.
우선, few - shot은 모든 prompt의 구성을 담고 있는 것을 위의 그림을 통해서 알 수 있습니다. 위에 그림을 보면, 영어를 불어로 바꾸는 task이고, 예제들이 존재하고 있고, 해당 예제를 통해서 무엇을 무엇으로 변환하면 좋을 지에대한 예가 있습니다. 마지막에 cheese를 번역하라는 prompt를 입력으로 주어 cheese를 gpt-3가 cheese를 불어로 번역을 할 도록 학습을 하는 방법을 사용하고 있습니다.
해당 few-shot learning은 3개의 예제가 있으므로, 3-shot learning이 있습니다.
one shot learning은 예제가 한개만 있는 경우에 해당합니다.
zero shot의 경우, task description만 있고, 예제가 없는 경우에 해당됩니다.
논문에서는 NLP task 전반에서 GPT-3가 상당한 성능을 보였다고 합니다. 몇 몇의 task들에서 few-shot, one-shot, zero-shot 셋팅에서 SOTA 수준을 넘었다고 합니다.
추론 혹은 도메인 적응이 필요한 task도 잘 수행한다고 합니다.
- (ex) 단어 순서 맞추기, 문장에서 새로운 단어 사용하기, 3자리 수리 연산하기
뉴스기사는 사람이 쓴 것과도 구분하기 어려웠다고 합니다. ANLI, RACE, QuAC 등 일부 데이터 셋에서의 경우 GPT-3로도 성능 달성이 어려운 경우도 있었다고 합니다.
GPT-3 모델은 Transformer의 Decoder 구조만을 사용해서 학습을 하였습니다. 기존에 Transformer에는 Self-Attention 구조를 사용하였으나 GPT-3에서는 Sparse Attention 구조를 사용했습니다. 정확히 어떤 구조인지는 나와있지 않았고, 이런 도식화된 그림만을 공개했습니다.
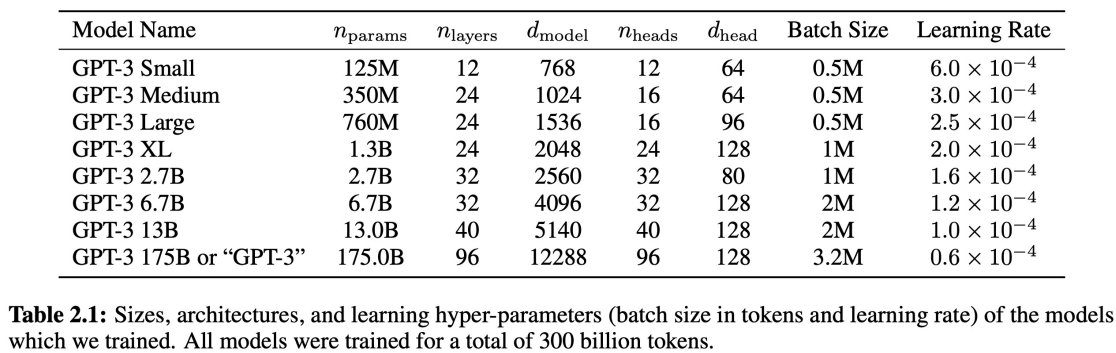
GPT-3는 서로 다른 크기의 모델 8개를 셋팅해서 학습을 진행했다고 합니다.
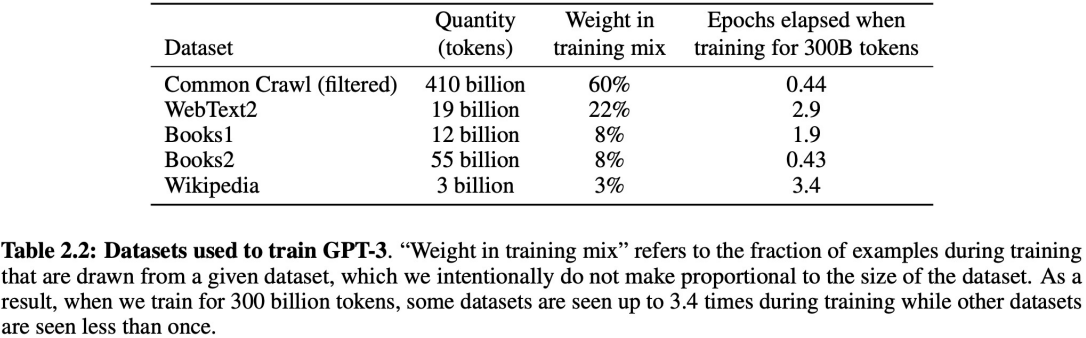
학습에 사용한 데이터 셋이고, weight in training mix는 학습 데이터 셋을 섞은 비율이라고 합니다.
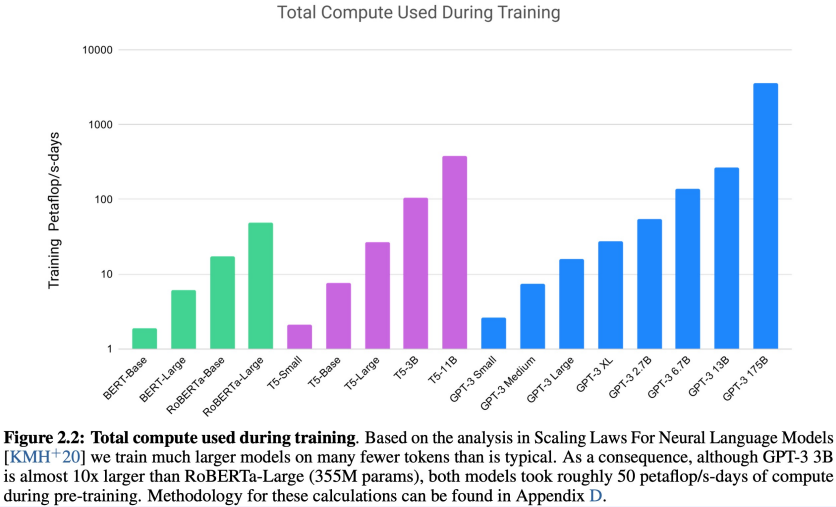
GPT-3 175B 모델의 경우 굉장히 많은 양의 계산이 필요하다라는 것을 알 수 있습니다.
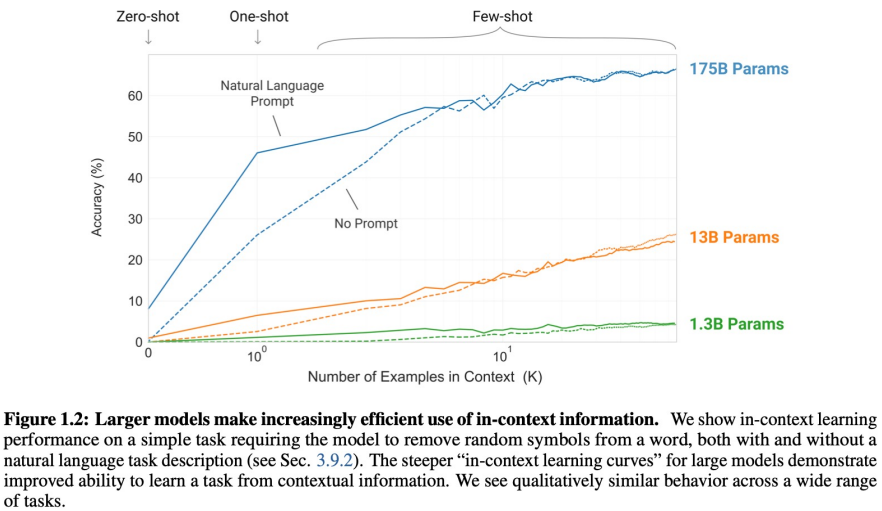
해당 그래프를 보면, meta learning 시에 example의 수가 많으면 많을 수록 모델의 성능이 증가된다는 것을 알 수 있습니다. 또한 모델의 크기가 증가하면 할 수 록 모델의 성능이 향상 되었고, Natural Language Prompt가 있는 경우에 더 학습이 잘 되는 것을 알 수 있습니다.
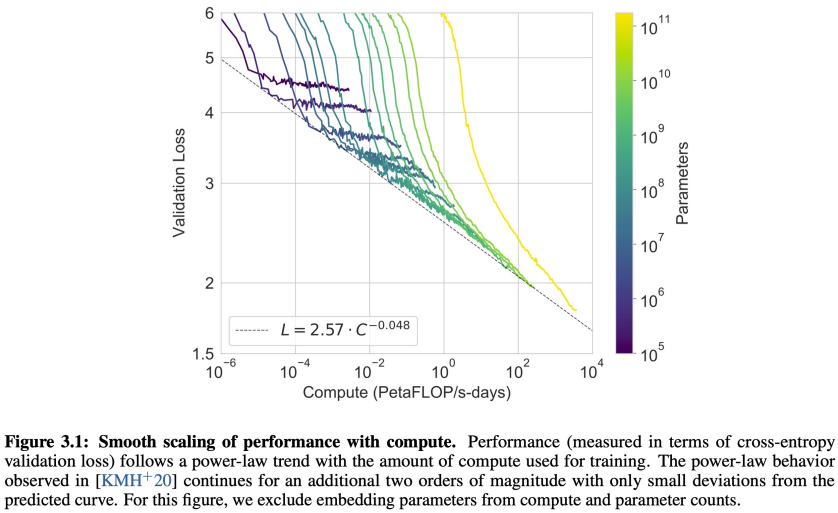
x축에서 왼쪽에서 오른쪽으로 갈 수록 큰 모델에 해당됩니다. 모델이 크면 클수록 validation loss가 감소하는 것으로 봐서 선형적이 관계가 있다는 것을 알 수 있고, validation loss의 최저점 또한 낮아짐을 알 수 있습니다.
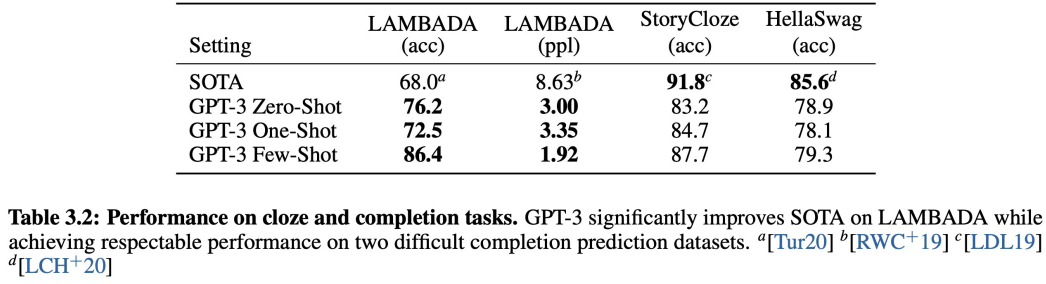
위의 그림은 각각에 데이터 셋에 GPT-3 모델이 SOTA를 달성한 모델을 이기거나 거의 근접한 성능을 보이는 것을 알 수 있습니다. 해당 task는 문장에 빈칸을 맞추는 task에 해당하는 데이터 셋들입니다.
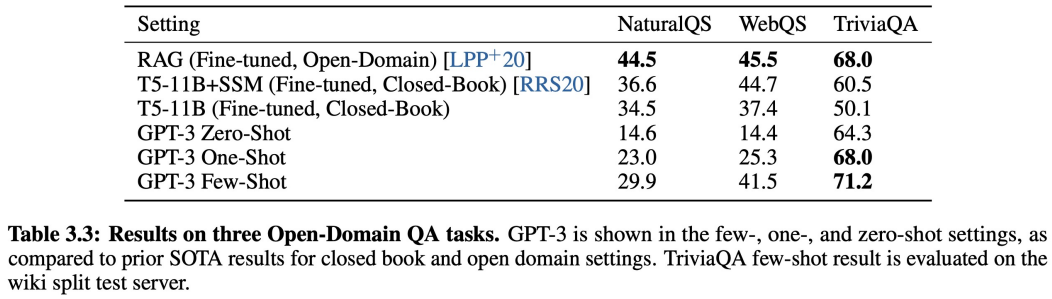
NaturalQS, WebQS는 잘 예측하지 못하고, TriviaQA 데이터 셋의 경우 SOTA를 달성 했습니다.
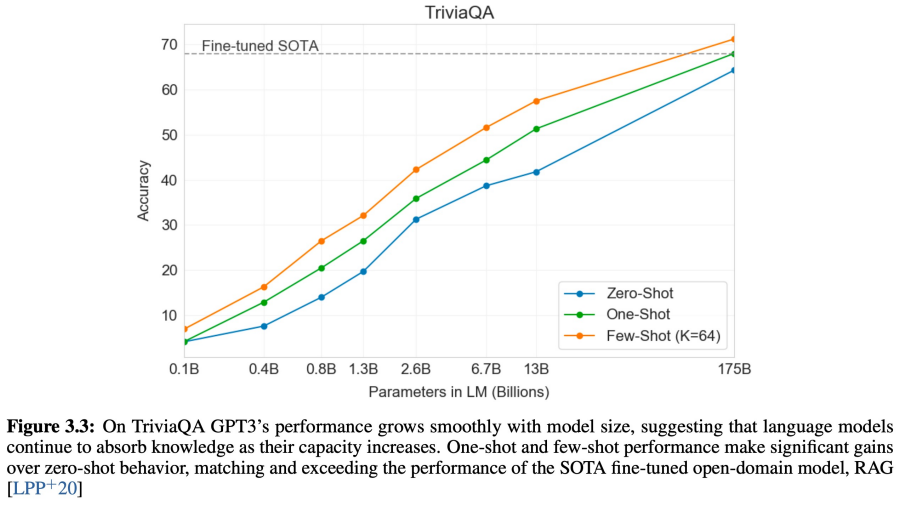
TriviaQA 데이터 셋으로 zero shot, one shot, few shot learning시에 모델의 성능 비교한 그래프 입니다. 해당 그래프를 보면, few shot learning으로 모델을 학습하면, 더 빠르게 SOTA를 달성하는 것을 알 수 있습니다.
이러한 실험 외에도 더 많은 양의 실험들이 있습니다.
이번에 일부 실험만 소개해드렸습니다 !! 혹시 더 궁금하신 분들은 논문을 살펴 보시는 것을 추천 드립니다.
'Large Language Model' 카테고리의 다른 글
| Numbers every LLM Developer should know (0) | 2023.08.07 |
|---|---|
| LLaMA Open and Efficient Foundation Language Models (1) | 2023.07.19 |
| Large Language Model의 역사 (1) | 2023.07.16 |
| LLM 트랜드-02 (0) | 2023.07.02 |
| LLM 트랜드-01 (0) | 2023.06.25 |



