LLaMA는 메타에서 등장했습니다 !!

라마는 7B ~ 65B 크기의 LLM 모델을 학습을 했습니다. 조단의에 토큰 수를 사용했습니다. LLaMA의 13B 모델이 GPT-3 (175B)의 모델을 이겼다고합니다. LLaMA-65B 모델은 Chinchilla-70B, PaLM-540B와 비슷한 수준이라고합니다.
LLaMA를 많이 사용하는 이유가 바로 OpenSource Community에 연구 용도로만 공개했습니다. LLaMA를 공개함으로 해서 많은 Chatgpt와 같은 모데들이 등장하고 있습니다.
LLaMA는 Transformer의 Decoder 구조만을 사용해서 학습을 했습니다. Transformer에서의 normalization을 pre-normaliza tion을로 변경해 학습을 했습니다(lay-norm -> pre-norm). LLaMA는 SwiGLU activation 함수를 사용했습니다. 또한 Position al embedding 중 하나를 차용해서 학습을 했습니다.
Optimizer 구성은 다음과 같습니다.
- AdamW, beta1 = 0.9, beta2 = 0.95
- cosine LR decay, minimum 0.1 * LR
- weight decay 0.1, gradient clipping 1.0, 2000 warmup

6.7B 모델을 보면 32개의 layer를 가지고 있고, 1.0T 토큰 수를 사용하고 있고, 65B 모델을 80개의 layer를 사용했고, 1.4T개의 token을 사용했습니다.

사용한 데이터 셋은 공개되어져 있고, 수집이 가능한 데이터 셋을 사용했습니다. 학습 셋은 tokenization 후 총 1.4T(1.4조개)의 토큰을 사용했습니다. 65B 모델에 1.4T 토큰을 사용할 시 학습에만 12일이 걸렸다고 합니다.

BoolQ 데이터셋 결과를 보면, LLaMA가 7B 모델임에도 불과하고, 175B의 parameter를 사용하는 GPT-3 모데를 이겼다고 합니다. 다른 데이터 셋에서도 SOTA를 달성하거나 전반적으로 좋은 성능을 보인다는 것을 알 수 있습니다.
라마의 경우, scaling rule을 조금 더 잘 따르며, 학습에 필요한 token수들을 굉장히 잘 계산해서 GPT-3에 비해서 최적화를 매우 잘한 모델입니다. 또한, 더 작은 모델로 더 좋은 달성 한 것을 알 수있습니다.

QA Task에서도 7B 모델만 보더라도 GPT-3 보다 좋거나 비슷한 성능을 보이며, 라마의 더 큰 모델들은 GPT-3의 성능을 능가했다는 것을 알 수 있습니다.
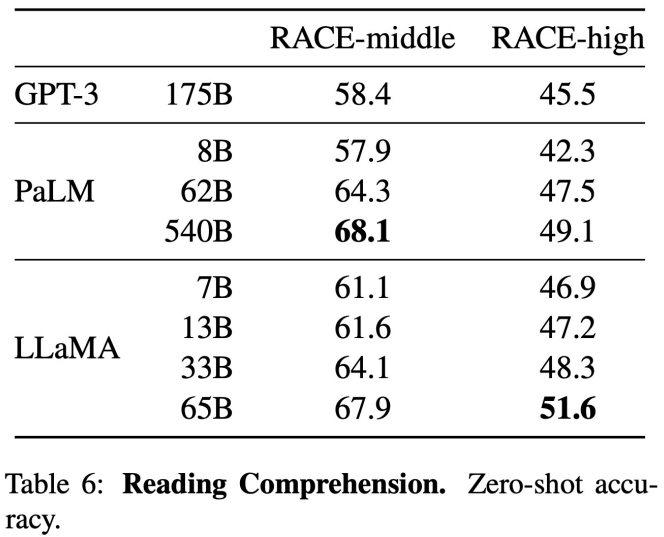
해당 Task에 대해서도, LLaMA는 GPT-3 보다 뛰어났고, PaLM과 비슷한 성능을 보이거나 성능이 더 좋기도 합니다.
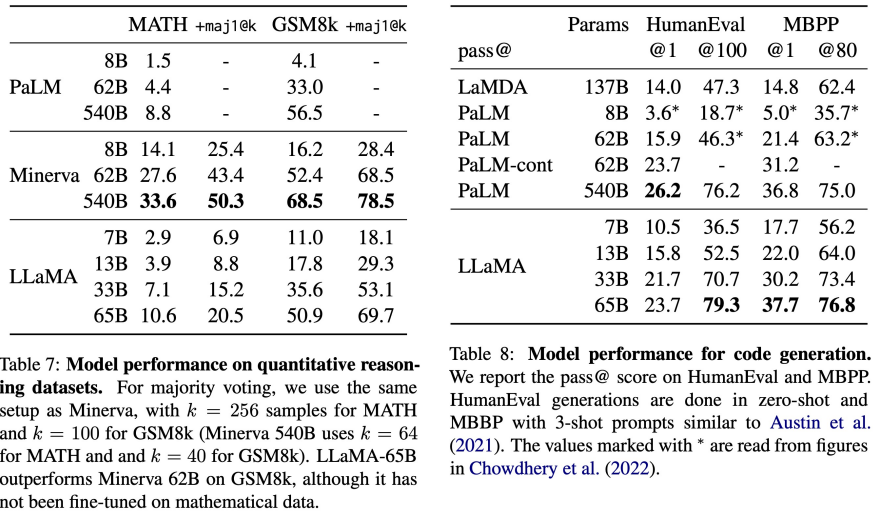
그 외에도 수학 문제에 대한 풀이와 code를 생성하는 Task에서도 전반적으로 좋은 성능을 보였습니다.
이러한 실험 외에도 많은 실험 결과들이 있습니다.
궁금하신 분들은 한 찾아보면 좋을 꺼 같습니다 !!
'Large Language Model' 카테고리의 다른 글
| Numbers every LLM Developer should know (0) | 2023.08.07 |
|---|---|
| Language Model are Few-Shot Learners (0) | 2023.07.16 |
| Large Language Model의 역사 (1) | 2023.07.16 |
| LLM 트랜드-02 (0) | 2023.07.02 |
| LLM 트랜드-01 (0) | 2023.06.25 |



