PETALS: Collaborative Inference and Fine-tuning of Large Models
1. Introduce
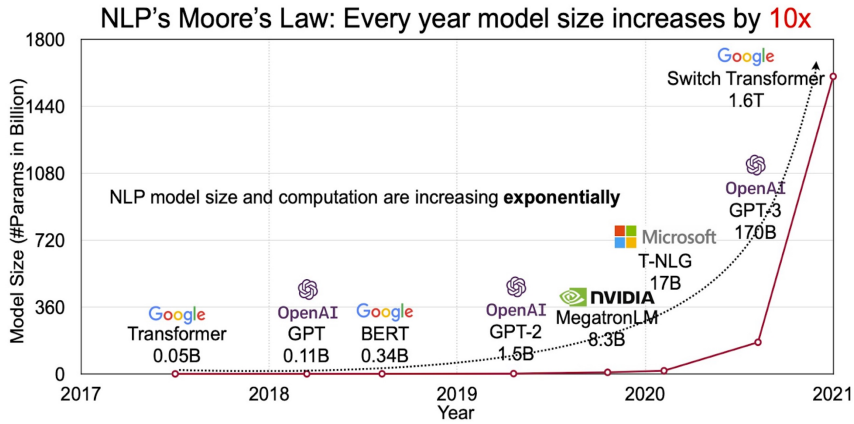
최근 LLM(Large Language Model)의 추세는 모델의 크기가 커지는 추세임을 알 수 있습니다. 최근에 출시된 LLaMA2는 175B의 크기인 GPT-3나 GPT-4에 비해서는 작지만 일반적인 장비로 모델을 개발하는 사람들에게는 해당 모델도 매우 큰 모델이라고 할 수 있습니다. 최근에 출시된 모델은 LLaMA2 뿐만 아니라 BLOOM-176B, OPT-175B 등등 많은 모델들이 있습니다. 해당 모델들이 공개 됨에 따라서 누구나 LLM 다운로드 받을 수 있게 되었습니다. 하지만, LLM을 사용하기 위해서는 고성능의 하드웨어가 필요합니다. 따라서 연구적인 측면에서 LLM에 유연하게 접근 할 수 없을 뿐더러, 고성능 하드웨어 장비가 없다는 물리적인 제약 또한 생기게 되었습니다.
논문에서는 LLM 연구를 위한 PETALS를 제안하며, PETALS는 LLM을 학습 시키기 위해 협업하는 다수의 사람과 GPU 자원들을 결합해서 LLM을 inference 시키고, fine-tuning을 수행 할 수 있게 해주는 시스템입니다. 논문에서는 CPU, GPU 오프로딩 보다 우수한 성능을 보여준다고 합니다. 논문에서는 소비자용 장비 즉, RTX 3060, RTX 2080Ti와 같은 장비에서도 LLM 어플리케이션을 충분히 제공할 수 있다고 합니다. 기존에 LLM에서 제공 했던 API와는 다르게 PETALS에서는 모델의 Hiddne States를 직접 노출 시키므로, 효율적으로 fine-tuning 할 수 있고, 사용자 정의 모델을 학습하고 공유할 수 있게 됩니다.
위의 사진처럼 LLM의 크기가 커지면서, 다양한 문제에 대한 해결 능력과 모델의 성능이 향상되는 것을 알 수 있지만, 모델이 커짐에 따라서 1000억개 이상의 parameter들을 가지고 있기에 고성능의 장비와 메모리 비용이 많이 들기 때문에 대부분의 연구자들은 사용하기 어려운 모델입니다. 예를 들어, BLOOM-178B 모델과 OPT-175B 모델의 경우, inference만을 위해서 350GB의 GPU 메모리를 필요하게 되고, 만약 fine-tuning을 하게 되면 더 많은 양의 메모리가 필요하게 됩니다. 따라서 LLM은 고성능 GPU들이 필요하기에 연구에 들어가는 비용이 많이 듭니다. 따라서, 최근에는 효율적으로 오프로딩을 하는 방법들을 통해서 사용하지 않는 parameter의 경우, RAM이나 SSD(NVMe)와 같은 장비에 오프로딩 시키고, 필요한 경우에만 GPU에 오프로딩 시켜서 학습하는 방법으로 LLM을 학습시키는 것을 목표로 하고 있습니다. 이와 같이 효율적으로 GPU 메모리를 사용하는 방법을 MS에서 개발한 Zero-dp zero-mp, zero-infinity와 같은 방법들이 있고, 해당 방법들은 사용해서 deepspeed나 허깅페이스에 accelerated를 통해서 사용할 수 있습니다.
하지만 이러한 오프로딩 방식의 학습법은 여러 토큰을 병렬로 처리하는 데 효율적일 수 있지만, 고유한 특성상 높은 대기 시간(latency)을 가지고 있습니다. 예를 들어, BLOOM-176B로 하나의 토큰을 생성하는 데에 최고의 성능을 가진 RAM 오프로딩 설정으로도 최소 5.5초가 소요되며, 가장 빠른 SSD 오프로딩 설정에서는 22초가 소요됩니다. 게다가 많은 컴퓨터들은 1750억 개의 파라미터를 언로딩하기에 충분한 RAM을 갖추고 있지 않습니다.
따라서 논문에서는 신경망의 크라우드소싱 분산 학습에서 아이디어를 얻어 대안적인 전략들을 탐구합니다. 따라서, 우리는 PETALS라는 플랫폼을 소개합니다. PETALS는 여러 사용자가 인터넷을 통해서 대규모의 언어 모델을 inference하고, fine tuning 할 수 있도록 해줍니다.

논문에서는 “서버에서 모델의 레이어 일부를 호스팅하고 클라이언트로부터의 요청을 처리한다고 합니다. 클라이언트는 연속적인 파이프라인 병렬 서버 체인을 구성하여 전체 모델의 추론을 실행할 수 있습니다.”라고 합니다. 제가 이해하기로는 LLM을 학습하고자 하는 사람들끼리 서버의 GPU를 병렬 적으로 연결을 해서 Transformer의 블록들을 나누어서 병렬적으로 연결된 GPU에 올리고, 올려진 layer의 순서에 따라서 클라이언트가 모델을 학습 시키기 위한 입력 데이터한 데이터를 pipeline - parallel을 사용해서 GPU에 올려진 Trasnformer의 layer에 순서대로 클라이언트의 요청을 처리해서 inference과 모델 학습을 할 수 있는 것으로 보입니다.
pipeline - parallel은 model parallel 방식의의 단점인 Idle time이 생기는 것을 방지하면서 효율적으로 GPU 메모리를 사용하면서 inference 속도의 개선과 학습 속도의 개선을 해서 사용한 것으로 보입니다.
추론 외에도, 참가자들은 어댑터 (Houlsby 등, 2019) 또는 프롬프트 튜닝 (Lester 등, 2021)과 같은 파라미터 효율적인 훈련 방법이나 전체 레이어를 훈련시킴으로써 모델을 세밀하게 조정할 수 있습니다.
훈련이 완료된 후, 서브모듈은 모델 허브(2.3 절)에 공유될 수 있으며, 다른 사용자들은 이를 추론이나 추가적인 훈련에 사용할 수 있습니다.
또한 논문에서는 몇 가지의 최적화 기법들의 도움으로 기존의 1000억개 이상의 모델들을 한정된 환경에서 효율적으로 실행과 최적화 할 수 있다는 것을 증명했다고 합니다. :
- 동정 양자화
- 낮은 대기 시간 연결에 우선 순위 부여
- 서버간의 부하 분산
여기서 동적 양자화란 조금 더 빠르게 inference하고 학습하기위해서 사용하는 방법입니다. 동적 양자화를 사용하면 여러가지 trade-off를 마주하게 됩니다. 모델을 개발하고 학습할 때, 신경망의 레이어나 parameter 수를 바꾸어 볼 수 있을 텐데, 그럴 때면 정확도와 모델의 규모나 응답 속도(또는 처리량) 사이에 trade-off 가 생기게 됩니다. 변화를 줄 때면 시간과 컴퓨터 자원이 많이 소모되는데, 이는 모델 학습 과정에 대해 반복 작업을 수행하기 때문입니다. 양자화 기법을 기법을 사용하면 모델의 학습이 끝난 후 성능과 모델의 정확도 사이에 trade-off를 줄 수 있게 될 것입니다. 정확도가 별로 손실되지 않으면서도 모델의 규모를 상당히 줄이면서 응답 시간도 감소시킬 수 있기에 동적 양자화를 사용합니다.
그렇다면, 신경망을 양자화 한다는 말은 무슨 말일까요 .. ? 신경망을 양자화 한다는 말은 가중치나 활성화 함수에서 정밀도가 낮은 정수 표현을 사용하도록 바꾼다는 것입니다. 즉, 모델의 학습은 f32로 학습이 되었지만, 우리는 f16이나 bf16, int16과 같은 표현으로 바꾸어 학습을 하거나 inference를 수행 한다는 의미입니다.
즉, 다음과 같이 모델이 입력이 되고, 저장이되는 parameter와 weight에 저장되는 수치의 비트수를 감소시켜서 CPU나 GPU에서 수행하는 연산의 처리량을 높이고 모델의 규모를 감소 시킬 수 있습니다.
이런 동적 양자화 방법에는 Mixed Precision이라는 방법이 있는데 이 방법은 모든 모델을 보편적으로 사용하는 방법입니다. Mixed Precision은 다음과 같이 GPU에 2가지 Parameter를 가지고 있게 합니다. 우리가 학습할 paramter의 비트수를 f16 이라고 가정하고 이를 Low Precision이라고 하고 기존에 모델이 가지고 있는 f32를 Full Precision이라고 합니다.
여기서 Low Precision의 경우, forward와 backward시에 weight를 업데이트 합니다. 즉, Full precision 모델의 weight를 살리면서, f16으로 계산된 gradient를 사용해서 weight를 업데이트 한다고 생각하면 됩니다.

2.1 inference of billon - scale model
토큰을 생성할 때, 클라이언트는 모델의 토큰 임베딩을 로컬에 저장하며, 이 임베딩은 일반적으로 총파라미터의 작은 부분에 해당 됩니다. 로컬에 저장되는 이 파라미터는 노트북, 서버 워크스테이션 등과 같은 ram에 적합하다고합니다. 즉, transformer 모델을 학습시키기 위해서는 입력 문장을 tokenizer를 통해서 token으로 만들어야 하는데, 이때 생성된 token들은 학습이 가능한 token들입니다. LLM 모델은 말그대로 매우 큰 모델에 해당합니다. 따라서 저장할 모델의 크기 또한 엄청 크다는 것을 알 수 있습니다. 따라서, 일반적인 사용자들은 peft 방식으로 학습 parameter 즉 token들을 학습한 parameter만을 local 저장을 합니다.
논문에서는 클라이언트가 학습할 모델을 병렬적으로 연결된 서버들에 GPU 메모리에 각 transformer 블록 단위로 나누어서 실행시키도록 한다고 합니다. 이때 클라이언트가 사용할 모델의 모든 레이어를 올릴 서버 체인을 찾고, 서버 체인을 찾으면, 병렬적으로 연결된 서버 체인이 형성이 됩니다. 각 서버는 연속된 transformer의 여러 블록들을 보유한다고 하며, 블록의 수는 서버에서 사용 가능한 GPU의 개수에 따라서 달라진다고 합니다. 그리고 로컬에 저장된 임베딩된 토큰들, 즉 우리가 학습 시킨 토큰들을 사용해서 새로운 입력에 대해서 토큰화 즉, 벡터화를 시키고, 서버 체인에 전송한 후에 새로운 표현들을 받아 온다고 합니다. 클라이언트가 최종 블록의 출력을 얻으면, 다음 토큰의 확률을 계산하고 이 프로세스를 반복한다고 합니다.
해당 세션이 활성화되는 동안에는 서버들은 과거 클라이언트 입력으로부터 얻은 어텐션 키와 값들을 저장하고 이를 이후의 추론 단계에 사용한다고 합니다. 클라이언트들은 또한 각 서버에 대한 과거 입력을 저장하여, 어떤 서버가 실패하거나 오프라인 상태가 되더라도 다른 서버가 빠르게 대체할 수 있도록 합니다. 서버를 찾는 절차와 장애 복구 과정에 대한 내용은 3.2절에서 자세히 설명되어 있습니다.
Client-slide API
PETALS를 사용하여 토큰을 생성하려면, 먼저 inference 세션을 생성합니다. inference 세션은 PyTorch 텐서로 입력을 받아 모든 Transformer 블록을 통과시킨 후 최종 표현을 PyTorch 텐서로 반환하는 방식으로 반복적으로 수행됩니다. 실제로 세션은 서버 체인을 형성하고 캐시를 유지하며, 사용자에게는 투명하게 서버 장애로부터 복구하는 방식으로 동작합니다. 추론 세션을 사용하는 예시는 Figure 2에서 보여집니다.

System requirements
논문에서는 BLOOM-176B 모델을 inference 하기 위해서는 클라이언트의 경우, 적어도 12GB 이상의 RAM이 필요하다고 하며, 그 중 대부분은 36억개에 해당하는 embedding parameter를 저장하는 데 사용한다고 합니다. PETALS는 네트워크를 통해서 서버를 병렬적으로 연결해서 서버 체인을 형성하기 때문에 네트워크 전송 상에서 병목 현상을 피하기 위해서 25Mbit/s 이상의 대역폭(양방향)을 권장한다고 합니다. 서버의 경우, Pytorch가 실행되는 어떤 CPU에서도 사용할 수 있지만, 더 발전된 알고리즘(ex: 빔 서치)의 경우, GPU를 필요로 할 수 있습니다. 또한 적어도 16GB CPU RAM과 100Mbit/s의 대역폭을 가지는 네트워크가 필요하고, GPU의 경우, 8GB의 VRAM이 필요하다고 합니다.
Chat Application
논문에서는 PETALS 라이브러리가 사용자들 간의 메신저(카카오톡, 인스타 DM 등등)과 유사한 사용자 인터페이스에서 LLM과 채팅(https://chat.petals.dev/)할 수 있는 예제 Application을 제공한다고 합니다.

해당 chatbot은 사용된 모델은 BLOOMZ-176B와 BLOOM-176B을 지원한다고 합니다. BLOOMZ-176B는 BLOOM을 zero-shot 환경에서 더 잘 수행하도록 세밀하게 조정한 버전입니다 (Muennighoff 등, 2022). 이 애플리케이션 은 프론트엔드와 백엔드로 구성되어 있습니다. 프론트엔드는 사용자가 텍스트로 모델에 프롬프트를 보내고 생성된 출력을 받을 수 있는 웹 페이지라고 하며, 백엔드는 Flask 웹 서버로, PETALS 클라이언트를 사용하여 inference를 실행한다고 합니다. 이 백엔드는 HTTP 또는 웹소켓 프로토콜을 통해 요청을 수락하므로, 논문에서는 누구나 백엔드를 사용하여 자신만의 애플리케이션을 개발할 수 있다고 합니다.
2.2 Training for downstream tasks
저자는 LLMs은 간단한 프롬프트 엔지니어링으로 많은 문제에서 높은 품질의 답변을 얻거나 원하는 목표를 달성할 수 있지만 (Brown 등, 2020), 현재 가지고 있는 데이터 셋에 최적화된 결과를 얻기 위해서는 훈련이 필요하다고 합니다. LLM과 같이 거대한 모델이 등장하기 전에는 해당 문제에 대해서 downstream task에 대해 모든 모델 파라미터를 fine-tuning하는 것으로 현재 가지고 있는 데이터 셋에 최적화된 결과를 얻을 수 있었습니다. 그러나 LLM과 같은 매우 거대한 모델의 경우에는 fine-tuning으로 custom 데이터 셋에 최적화된 결과를 얻기 위해서는 하드웨어에만 천문학적인 비용이 요구됩니다. 예를 들어, Adam으로 BLOOM-176B를 fine-tuning하는 경우에, gradient 및 optimizer를 저장하기 위해 거의 3TB의 GPU 메모리가 필요합니다.
이러한 초거대 모델을 학습 시키기 위해서 NLP 커뮤니티에서는 parameter-efficient fine-tuning(peft)라는 방법을 사용해서 전체 parameter를 학습하는 것이 아닌 일부분의 parameter를 선택해서 학습하는 방식으로 동작을 합니다(Sung 등, 2021; Guo 등, 2021). 다른 몇몇은 모델을 추가적인 학습 가능한 가중치로 보강하는 방식으로 동작합니다 (Hu 등, 2021; Houlsby 등, 2019; Liu 등, 2021b; Lester 등, 2021; Liu 등, 2021a, 2022a). 낮은 메모리 요구 사항으로 인해서 parameter-efficient fine-tuning(peft)라는 접근 방법은 모델 fine-tuning 모델들과도 비슷한 성능을 보이고 있다고 하며 (Hu 등, 2021; Liu 등, 2021a; Yong와 Nikoulina, 2022), 작은 데이터와 낮은 하드웨어 환경에서도 우수한 성능의 모델을 만들 수 있다고 합니다. parameter-efficient fine-tuning(peft) 방식의 접근 방법의 장점은 LLM을 빠르게 다양한 용도로 전환해서 사용할 수 있다는 점이라고 합니다.

Distributed fine-tuning
Distributed Network에서 fine-tuning의 핵심 원칙은 클라이언트가 훈련된 파라미터를 "소유"하고 서버가 원래 미리 학습된 레이어를 호스팅한다는 것입니다. 서버는 자신의 레이어를 통해 역전파를 실행하고 activation에 대한 gradient를 반환할 수 있지만, server-side parameter를 업데이트 하지 않는다고 합니다. 즉, 클라이언트는 서로 간섭하지 않고 동일한 서버 집합에서 서로 다른 training을 동시에 수행할 수 있다고 합니다.
위에서 설명했듯이 pipeline parallel은 model parallel 방식의의 단점인 Idle time이 생기는 것을 방지하면서 효율적으로 GPU 메모리를 사용하면서 inference 속도의 개선과 학습 속도의 개선할 수 있다는 장점이 있는 동시에 논문에서 설명한 것처럼 동시에 여러 task에 대한 학습도 진행이 가능합니다.
server-side parameter를 업데이트 하지 않는다.란 의미는 제가 이해하기로는 우선 mixed - precision에 기반한 학습 방법에 대한 설명인 듯 보입니다. 따라서 해당 학습 방법을 적용하면, GPU에 2개의 parameter가 올라가게 됩니다. 하나는 모델이 원래 가지고 있던 파라미터인 f32에 해당하는 parameter 이고, 다른 하나는 모델을 업데이트하면서 생성된 f16 paramter입니다. mixed - precision 방법으로 학습을 하게 되면, 원래 기존에 가지고 있던 모델의 paramter를 가지고 있으면서, 동적 양자화를 통해서 업데이트한 f16 paramter만을 로컬에 저장할 수 있게 됩니다.
해당 방법이 가능한 이유는 클라이언트는 임베딩 레이어를 로컬에 저장하고, Transformer 블록에 대한 activation의 gradient의 계산은 서버에 의존을 합니다. 따라서 클라이언트는 soft prompt와 linear classification head를 저장해야한다고 합니다.
훈련은 각 훈련 배치마다 클라이언트는 데이터를 원격 서버 체인을 통해 전달하여 문장 표현을 계산한 다음에 classification head로부터 예측을 얻고 cross entropy loss을 계산합니다. 역전파 과정에서, 클라이언트는 학습된 프롬프트 벡터에 대한 그래디언트를 계산하기 위해 동일한 서버 체인을 역순으로 실행합니다. 이렇게 계산한 그래디언트를 얻은 후, 클라이언트는 일반적인 PyTorch optimizer를 사용하여 head와 prompt의 파라미터를 업데이트하고, 다음 미니배치로 진행할 수 있습니다.
User inference
사용자들이 훈련 작업 부하에 대해 보다 큰 유연성을 갖도록 하기 위해, 논문에서는 분산 역전파 모듈을 PyTorch Autograd 엔진과 호환 가능하도록 만들었다고 합니다. Inference 단계에서도 마찬가지로, 이 모듈은 사용자에게 투명하게 장애 허용과 부하 분산을 처리하면서 중간 활성화에 접근하고 사용자 정의 PyTorch 모듈을 삽입할 수 있도록 합니다. Figure 4는 훈련 코드 스니펫의 예시를 보여줍니다.

이 인터페이스는 또한 다른 인기 있는 PEFT 알고리즘인 LoRA (Hu 등, 2021) 또는 prefix tuning (Li와 Liang, 2021)과 같은 방법을 지원한다고 합니다. 마지막으로, 사용자들은 기존 블록들 이후에 사용자 정의 로컬 모듈을 삽입할 수 있으며, 이는 retrieval-augmented generation (Borgeaud 등, 2021; Lewis 등, 2020)과 같은 사용 사례를 가능하게 할 수 있습니다.
해당 부분은 연구자들이 PEFT에는 여러가지 방법이 있는데 그중 하나가 새로운 데이터 셋에 대해서 기존 모델의 Paramter는 그대로 두고 새로운 데이터 셋에 대한 새로운 Parameter에 대해서만 학습을 하는 경우가 있고, transformer 사이에 새로운 block을 추가하거나 Side-block을 추가해서 PEFT를 수행할 수있는데 논문에서 “사용자 정의 로컬 모듈을 삽입”은 연구적인 측면으로 연구자가 개발한 모듈 또한 삽임함으로 해서 모델을의 성능을 끌어 올리는 연구 또한 가능하다는 것입니다.
2.3 Sharing and reusing trained modules
논문에서는 대부분의 pre-trained된 모델에 대한 fine tuning으로 확장된 모델을 그대로 공유할 수도 있지만, 이러한 확장 공유하기 하기 위해서는 워크플로우를 가소화해서 사용자들이 모델을 원하는 시나리오에 더 쉽게 적응 시킬 수 있다고 합니다. 논문에서는 기존의 모델 허브들 (Wolf 등, 2020; TensorFlow Hub; PyTorch Hub)은 많은 지원 모델과 사용의 편리함으로 인해 특히 주어진 문제에 대해 다양한 미리 학습된 모델을 검토할 때 큰 인기를 얻었습니다. 라고합니다.
AdapterHub (Pfeiffer 등, 2020)는 훈련된 어댑터들이 포함된 저장소로, 다양한 적응 방법의 구현을 제공하는 라이브러리와 함께 제공되는 특히 관련성이 있는 프로젝트 입니다. PETALS는 AdapterHub에 의존하지 않지만, 분산 환경에서 어댑터를 훈련하기 위해 이 라이브러리를 활용하는 것이 가능하고 사용자들에 의해 훈련된 모듈을 Hugging Face Hub를 통해서 학습 모델을 공유하는 것을 지원 한다고 합니다. 또한, Hugging Face Hub의 인프라와 해당 오픈소스 라이브러리는 이미 해당 생태계에 익숙한 사용자들에게 학습 과정을 간소화하는데 도움이 되며, 따라서 사용자는 훈련된 작업과 어댑터가 구축된 모델만 알면, fine-tuning 된 모듈의 가중치와 코드를 업로드하는 작업은 해당 내용을 Git 리포지토리에 커밋하는 것으로 이루어진다고 합니다. Hub를 탐색하는 동안, 사용자들은 필요한 태그로 모든 가능한 모듈의 목록을 필터링하여 가장 적합한 어댑터를 선택할 수도 있다고 합니다.
3. Internal structure and optimizations
논문에서는 분산 추론을 고려할 때 주요 고려 사항 중 하나는 성능이라고 하면, 이를 3가지 측면으로 나눌 수 있다고 합니다.
- 계산 속도 (5년 된 게이밍 GPU 대 최신 데이터 센터 GPU)
- 노드 간 거리에 따른 통신 지연 (대륙 간)
- 대역폭에 따른 통신 지연 (10 Mbit/s 대 10 Gbit/s).
논문에서는 Raw FLOP 기준으로, GeForce RTX 3070과 같은 소비자용 GPU를 사용해서 BLOOM-176B 의 전체 inference 단계를 1초 이내에 완료할 수 있었다고 합니다(NVIDIA, 2020). 하지만 GPU 메모리는 모델 레이어의 일부만을 저장할 수 있습니다. 하지만 실행하기 위해서는 최소 44개 의 RTX 3070 GPU와 44회의 통신 라운드가 필요하다고 합니다. 논문에서는 더 효율적으로 하기 위해 우리는 양자화를 사용하여 GPU에 저장되는 Parameter 양을 줄여서 GPU(float 32 비트를 float16 비트로 바꾸서 메모리를 차지하는 paramter의 크기를 줄인다고 생각하시면 됩니다. 또한 연산 속도도 빨라집니다.) 당 더 많은 파라미터를 저장할 수 있게 하고, 연속적인 장치와 통신 라운드의 수를 줄였다고 합니다.
3.1 Large Model inference on consumer GPUs
논문에서는 각 서버가 가지는 최소한의 사양을 16GB의 CPU 메모리와 8GB의 GPU 메모리를 가지고 있는 PC라고 서버라고 가정 했다고 합니다. 이 가정의 주요 고려 사항 중 하나는 모델이 차지하는 메모리양을 줄이면서, 각 장치가 더 많은 Transformer 블록을 보유할 수 있도록 하기 위해서라고합니다.
BLOOM 모델이 가지고 있는 Parameter의 양은 176B있습니다. 해당 모델을 16비트로 GPU 메모리에 업로드하기 위해서는 352GB의 GPU 메모리가 필요합니다. 따라서 최악의 경우 352/8 = 44개의 노드로 분산됩니다. 논문에서는 2가지 방법으로 데이터 전송의 빈도와 양을 줄일 수 있다고 합니다.
- 노드 간 교환되는 hidden states를 압축하여 데이터 전송
- 가중치를 8비트 정밀도로 압축하여 모든 레이어를 보유하는 데 필요한 노드 수 감소.
논문에서는 위 2가지 방법을 사용한다면 BLOOM의 경우, 필요한 노드 수가 44개에서 22개로 줄어들어서 지연 시간이 절반이 되고 서버 장애로 인한 학습이 불가능한 상황에 대한 가능성이 감소한다고 합니다.
Compressing communication buffers.
논문에서는 연속적인 파이프라인 단계 간에 적은 데이터를 보내기 위해, 동적 블록 단위 양자화(Dynamic blockwise quantization)를 사용한다고 합니다(Dettmers 등, 2022b). 논문에서는 이것을 pipeline-parallel 통신 이전의 hidden states에 적용한다고 합니다.
pipeline-parallel은 model parallel시에 나타나는 Idle Time을 해결하고 나온 방법입니다. model parallel은 여러 GPU 메모리에 모델을 나누어 올리고 데이터를 들어오면, 0 , 1, 2, 3(GPU가 4개 있다고 가정) 순서로 Model을 통과합니다. 하지만 0 번째 GPU에서 작업이 완료가 되고, GPU 1로 feature를 넘기면 다음 배치가 올 때까지 GPU-0번은 아무 일도 하지 않게 되는 이를 Idle Time이라고 합니다. 해당 상황을 해결하고자 GPU 1로 feature를 넘기면 GPU 0번에 다음 batch에 관한 데이터의 feature를 계산하도록 하며, 0 번째 배치, 1번째 배치 순서로 역전파도 이루어 집니다. (0번은 역전파 , 1번은 아직 모델 통과중)이전의 hidden states 즉, 0번 batch의 파라미터를 업데이트를 f32로 학습된 파라미터를 f16으로 업데이트 하는 내용이라고 이해하심 됩니다. f32로 학습된 파라미터를 f16으로 업데이트 하는 parameter도 모델 전체를 하는 것이 아닌 f16으로 업데이트 하는 일부 parameter에 한해서 이루어 지는 것입니다.
동적 블록 단위 양자화(Dynamic blockwise quantization)는 생성 품질에 눈에 띄는 영향 없이 대역폭 요구 사항을 반으로 줄여준다고 합니다.
Compressing model weights.
논문에서는 8비트 혼합 행렬 분해를 행렬 곱셈에 사용하여 가중치를 8비트 정밀도로 양자 화하고, 16비트 가중치와 비교하여 메모리 풋프린트를 줄이는 것을 (Dettmers 등, 202 2a)에서 제안한 대로 하였습니다. 논문에서는 hidden states와 가중치를 두 부분으로 분리한다고 합니다. 이로 인해 16비트의 이상치가 약 0.1%이고, 8비트의 정상 값이 약 99.9%가 되어 메모리 풋프린트가 대략 반으로 줄어든다고 합니다.

논문에서 실험한 결과인 Table 1을 보면, 해당 방법을 사용 했을 경우에 주요 벤치마크에 대한 LLM 품질에 거의 영향이 가지 않는다고합니다. inference 시간 측면에서, Table 2는 배치 크기 1 (20 토큰)에서 양자 약 5%의 오버헤드를 가지지만, 더 큰 배치에서는 무시할 정도로 작아진다는 것을 보여줍니다.
3.2 Collaborating over the Internet
논문에서는 서버 노드가 언제든지 이탈하고, 합류, 또는 모델 학습 및 inference에 실패하더라도 신뢰할 수 있는 inference와 훈련을 제공하는 방법에 대해서 이야기합니다. PETALS 라이브러리는 분산 훈련을 위해 hivemind 라이브러리 (Learning@home, 2020)를 사용하고, 서버와 클라이언트에 대해 사용자 정의 용량 탄력적인 프로토콜을 사용한다고 합니다.
Server load balancing
논문에서는 먼저 Transformer 블록들이 서버들 사이에서 고르게 분포 될 수 있도록 보장해야 된다고 합니다. 서버에서 가장 나쁜처리량을 가진 블록을 선택하고 잠재적인 병목 현상을 제거하여(해당 서버 노드를 제거한다는 것 같음) 전체 모델처리량을 최대화한다고 합니다. 각 서버는 주기적으로 활성 블록들을 분산해시 테이블에 공지한다고 합니다(Maymounkov와 Mazieres, 2002).
논문에서는 만약 새 서버가 합류하면 이러한 정보를 사용하여 처리량이 가장 적은 대부분의 블록이 포함된 블록의 간격을 식별한다고 하며, 해당 간격은 항상 연속적이며, 분할하면 추론 지연이 발생하기 때문에 그대로 유지된다고 합니다. 서버가 자신의 레이어를 선택하면, 네트워크와 컴퓨팅의 처리량을 측정하고 이를 분산 해시 테이블에 공지합니다. 동료 노드들이 언제든지 나가거나 실패할 수 있으므로, 모든 노드는 주기적으로 리밸런싱 절차를 실행하여 전체적인 처리량을 크게 개선할 수 있는지 확인합니다. 그렇다면, 노드들은 레이어를 변경하여 처리량이 최적에 근접하도록 만듭니다. 특히, 특정 블록을 서비스하는 모든 동료들이 갑자기 시스템을 떠난 경우, 이 절차는 남아있는 자원을 빠르게 재분배하여 생긴 빈 공간을 채우게 됩니다.
Client-side routing
논문에서는 그 다음으로, 클라이언트가 모델을 가장 적은 시간으로 실행하는 서버 시퀀스를 찾을 수 있도록 한다고 합니다. 생성 중에 클라이언트는 한 번에 하나 또는 몇 개의 토큰을 처리하기 때문에 실제로 inference 시간은 대부분 네트워크 지연에 민감해 진다고 합니다. 따라서 클라이언트는 근처 서버에 ping을 보내 지연 시간을 측정한 다음 빔 서치를 통해서 최소 시간 경로를 찾아야 한다고 합니다.
반면에, fine-tuning 중에는 여러 예제의 배치를 병렬로 처리해야 하며, 여기서 클라이언트들은 Ryabinin et al. (2023)의 알고리즘을 사용하여 배치를 여러 서버에 분할할 수 있다고 합니다. 만약 서버가 훈련이나 추론 중에 실패하면, 클라이언트는 해당 서버를 제외하고 대체 서버를 찾기 위해 라우팅을 다시 실행하며, 추론 중에 클라이언트는 모든 이전 입력을 대체 서버에 보내어 동일한 attention key 와 value들을 가지도록 한다고 합니다.
3.3 Benchmarks
논문에서는 PETALS의 성능을 평가하기 위해 BLOOM-176B를 에뮬레이션 및 실제 환경에 서 실행하며, 첫 번째 설정은 각각 A100 80GB GPU에서 실행되는 3개의 로컬 서버로 구성하며, 이것은 최소한의 통신이 필요한 낙관적인 시나리오라고 합니다.
두 번째 설정에서는 각 A100-80GB를 여러 가상 서버로 분할하여 12개의 더 약한 장치를 시뮬레이션한다고합니다 (3개의 큰 서버와 1개의 작은 서버). 논문에서는 위의 설정들을 세 가지 네트워크 구성으로 평가합니다:
- 1 Gbit/s와 < 5 ms 지연 시간
- 100 Mbit/s와 < 5 ms 지연 시간
- 100 Mbit/s와 100ms 지연 시간
클라이언트의 경우, 8개의 코어를 가진 CPU와 GPU는 없다고 합니다.
논문에서는 다음으로, 우리는 BLOOM을 14개의 작은 서버에서 벤치마크를 수행한다고 하며, 이 서버들은 2개의 RTX 3060, 4개의 2080Ti, 2개의 3090, 2개의 A4000, 그리고 4개의 A5000 GPU를 가지고 있다고 합니다. 이들은 개인 서버와 대학 연구소의 서버로 유럽과 북미 전역에 분산 되어 있으며, 인터넷 연결 속도는 100-1000 Mbit/s입니다. 이 중 4개의 서버는 방화벽 내에서 작동한다고 합니다.

Table 3에서는 single batch inference와 parallel forward pass의 성능을 보여준다고 하며, inference의 성능은 대역폭이나 시퀀스 길이에 크게 의존하지 않지만, 높은 지연 시간으로 저하됩니다. 대규모 배치로 수행되는 parallel forward pass(편집 및 병렬 추론에 사용됨)는 대역 폭과 지연 시간에 모두 영향을 받는다고 합니다.
논문에서는 또한 여러 클라이언트가 있는 경우의 효과도 테스트 했다고 합니다. 100 Mbit/s 대역폭과 100 ms 지연 시간을 가진 12개의 서버에서, 만약 8개의 클라이언트가 동시에 inference를 수행 한다면, 각각의 클라이언트는 혼자 inference를 실행할 때와 비교하서 약 20% 정도 느려진다고 합니다. 논문은 제한된 자원으로 큰 모델을 실행하는데, 사용되는 PETALS와 파라미터 오프로딩(Ren et al., 2021; Rajbhandari et al., 2021)을 비교했다고 합니다. 오프로딩 벤치마크에서는 오프로딩 성능의 상한을 얻기 위해서 inference와 forward pass 훈련 처리량을 계산한다고 하며, 오프로딩을 하기 위한 고성능 하드웨어를 기반으로하며, 16개 GPU를 PCIe 4.0을 통해서 연결했고, CPU RAM 오프로딩과 GPU 간의 PCIe 스위치를 사용한다고 합니다.
오프로딩의 최대 처리량을 다음과 같이 계산한다고 합니다. 8비트로 계산할 때는 모델은 10억 개의 파라미터 당 1GB의 메모리를 사용하며, PCIe 4.0은 16 레인을 통해 256 Gbit/s (또는 두 개의 GPU가 PCIe 스위치 뒤에 있는 경우 128 Gbit/s)의 처리량을 가진다고합니다. 따라서 176B에 해당하는 모델의 파라미터를 오프로딩하는데 정상적인 설정에서는 5.5초, multi-GPU 설정에서는 11초가 소요되며, 우리는 상한 추정을 위해 오프로딩 지연 시간을 0으로 가정한다고 합니다.
이러한 결과는 표 3에도 나와 있다고 합니다. 오프로딩 방법이 PETALS에 비해 단일 배치 추론에서는 한 차원 정도 느린 것으로 나타나며, fine tuning의 forward pass에서는 Multi - GPU를 사용하고 PETALS의 네트워킹이 100 Mbit/s로 제한되거나 지연이 높은 경우에 오프로딩 방법과 경쟁력이 있다고합니다. 그 외의 경우에는 PETALS가 학습을 위한 오프로딩보다 더 높은 처리량을 제공한다고합니다.
4. Discussion and future work
Incentives for peers to contribute.
PETALS에서, 클라이언트를 사용하는 피어들은 반드시 서버를 운영할 필요가 없습니다. 이로 인해 네트워크에서 공급(모델 레이어를 서빙하기 위해 GPU를 할당하는 피어들)과 수요(자신의 요구에 따라 inference이나 fine tuning을 위해 서버를 사용하는 피어들) 사이에 불균형이 생길 수 있지만, 사용자들에게 모델 레이어를 서빙하도록 유도하기 위한 한 가지 방법은 인센티브 시스템을 도입하는 것입니다.
서버를 운영하는 피어들은 특별한 포인트를 얻어냄으로써, 이 포인트를 우선순위가 높은 inference이나 fine - tuning에 사용하거나 다른 보상으로 교환할 수 있다고 합니다.
Privacy
논문에서는 접근 방식의 중요한 한계는 모델의 첫 번째 레이어를 서빙하는 피어들이 입력 토큰을 복구하는 데에 사용할 수 있다는 것입니다. 따라서 민감한 데이터를 다루는 사람들은 신뢰할 수 있는 서버만을 사용하거나, 대안으로 자체적으로 격리된 PETALS 스웜을 설정하는 것이 좋다고 합니다.
이러한 한계는 앞으로는 안전한 다중 파티 컴퓨팅(Evans et al., 2018) 또는 개인 정보 보호 하드웨어(NVIDIA, 2022)를 사용하여 해결할 수 있다고 합니다.
Security
논문에서는 시스템의 서버들은 많은 독립적인 당사자들에 의해 운영되고 있다고 가정 하지만 실제로는 그 중 일부가 결함이 있거나 실제로 실행한 결과가 아닌 잘못된 출력을 반환할 수도 있습니다. 이는 다른 사람들의 출력을 영향 주기 위한 악의적인 의도로 발생할 수도 있고, 보상이 도입될 경우 (위에서 설명한 것처럼) 실제로 계산을 수행하지 않고도 레이어를 제공하여 보상을 얻으려는 목적으로 발생할 수도 있습니다.
논문에서는 이러한 문제를 해결하기 위해서 가능한 방법은 경제적인 동기를 부여하는 접근 방식을 사용하는 것입니다. 일부 서버에 대해서는 정확한 출력에 대해 보증할 수 있도록 (예를 들어 높은 추론 가격과 교환으로) 일정 수의 포인트를 예치하는 것으로 해결 할 수 있으며, 각 요청에 대해서 입력과 출력 텐서의 암호화 해시를 발표하여 입력을 가진 사람은 출력이 올바른지 확인할 수 있습니다.
만약 누군가가 신뢰할 수 있는 제3자에 의해서 정확하지 않은 결과를 발견한다면, 서버의 예치금을 보상으로 청구할 수 있고, 실제로 잘못된 출력을 받았다고 의심하는 클라이언트나 오류를 발견하기 위해 서로 다른 서버에 요청을 보내는 "바운티 헌터"일 수 있습니다. 이 접근 방식은 여전히 잘못된 출력을 받을 수 있는 여지를 가지고 있지만, 부정행위에 대한 비용이 많이 드는 것으로 만들며 악의적인 서버를 빨리 노출 시키는 수 있다고 합니다. → 서로가 서로를 감시하도록 유도
Making changes to the main model
논문에서는 2.2절에서 설명한 LLM의 PEFT는 사용자가 base 모델에 새로운 task를 쉽게 적용할 수 있도록 해준다고 하며, 또한 2.3절에서는 이러한 업데이트를 쉽게 공유하고 다른 사용자들이 재사용할 수 있도록 설명했습니다. 이 기능은 기계 학습 모델의 공동 개선을 향한 의미 있는 단계를 제공한다고 합니다. (Raffel, 2021) 따라서 점점 더 많은 사용자가 base 모델을 학습하면 시간이 지남에 따라서 모델의 성능이 효율적으로 강해진다고 합니다.
또한, 특정 작업에 가장 우수한 성능을 발휘하는 모델 파라미터는 시간이 지남에 따라 변경될 수 있다고 기대할 수 있습니다. 코드의 버전 관리 시스템과 유사하게, fine tuning된 모델 파라미터의 버전을 추적하는 것이 유용할 것입니다. "실시간 벤치마크" (Kiela 등, 2021; Gehrmann 등, 2022; Gao 등, 2021)에서 일련의 파라미터의 성능을 신속하게 테스트하는 시스템은 이후 버전이 원하는 기능을 개선하는지 확인하는 데 유용할 것이라고 합니다.
새로운 Task에도 모델이 적응하는 것 외에도, 주요 모델을 최종적으로 업데이트하는 것에서도 유용할 수 있다고 하며, 이러한 업데이트는 원칙적인 방법으로 추적하는 것이 이상적이라고 합니다. 따라서 논문에서는 PETALS 라이브러리의 사용자는 사용하려는 모델의 버전을 지정할 수 있으며, 서버는 지원하는 버전을 나타낼 수 있다고 합니다. 그런 다음 모델의 새로운 버전을 도입하는 것은(모델의 구조 변경을 통한 성능 개선) 새로운 그룹의 레이어를 추가하는 것으로 간단해질 수 있으며, 이후 Section 3.2에서 설명한 방법에 따라 이전 파라미터를 자연스럽게 대체합니다. 마찬가지로, fine - tuning된 어댑터는 해당하는 모델 버전을 나타내는 태그로 표시될 수 있다고 합니다. 이러한 fine-tuning 모델 버전 관리는 현재 흔하지는 않지만 PETALS에 쉽게 추가할 수도 있다고 합니다.
5. Conclusion
이 논문은 PETALS라는 대형 언어 모델의 효율적인 공동 추론과 미세 조정을 위한 시스템을 소개합니다. 논문에서는 사용자 친화적인 인터페이스와 유연한 API를 제공하여 인터넷 상에서 제공되는 모델에 접근할 수 있도록 하고, 또한 매우 큰 모델을 실행하는 데 필요한 자원 요구 사항을 줄이기 위해 8비트 압축을 사용합니다(동적 양자화). 또한 신뢰할 수 있는 라우팅과 부하 균형을 위한 알고리즘을 개발하였습니다. 이 시스템의 출시로, LLM에 대한 접근성을 확대하고 이전에 불가능하거나 너무 비싼 응용 프로그램, 연구 또는 연구 주제에 대한 가능성을 열어두기를 기대합니다.
Ethics Statement
이 연구는 대규모 모델의 탈중앙화된 추론을 위한 일반적인 알고리즘을 소개하며, 딥 러닝 분야의 최신 연구에 대한 접근을 단순화하는 것을 목표로 합니다. 따라서, 우리의 연구로 인한 직접적인 부정적 영향은 없다고 생각된다고 하며, 우리는 폭넓은 대중들이 정돈되지 않은 웹 크롤링 데이터로 훈련된 LLMs와 상호 작용할 수 있는 능력을 갖게 될 것이라고 합니다. 그러나 우리가 제공하는 모든 모델은 이미 오픈 액세스이며, 따라서 API나 기타 방법을 통해 노출될 수 있다고 합니다.
'논문 정리' 카테고리의 다른 글
| WSI-VQA: Interpreting Whole Slide Images by Generative Visual Question Answering (7) | 2024.09.18 |
|---|---|
| [간단리뷰]Unet++ (0) | 2024.05.11 |
| YOLOV1 (0) | 2023.07.02 |
| Faster R-CNN (0) | 2023.06.24 |
| Fast R-CNN (0) | 2023.06.03 |



